
DB에서는 하나의 테이블에 여러 트랜잭션이 걸리는 동시성 문제가 발생 할 수 있다. 동시성 문제는 운이 없을 때만 발생하기에 테스트로 발견 하기 어렵다. 따라서 동시성 문제가 큰 이슈가 되는 결제, 송금 같은 경우에는 Serializable(직렬성) 격리를 사용한다. 하지만 Serializable은 오버헤드가 크게 발생하기 때문에, 비교적 동시성 문제가 크지 않을 때는 완화된 격리 수준을 사용한다. 이때 Serializable, 완화된 격리(read commited, repeatable read, dirty read)등이 Isolation Level이다.
Read Committed
Read Committed 수준에서는
- dirty read를 막아준다.
- dirty wirte를 막아준다.
이렇게 2가지를 보장해 준다.
Dirty Read
dirty read란 아직 트랜잭션이 커밋되지 않은 데이터를 읽어 오는 것을 의미한다.

dirty read를 허용하지 않는 이유
- 예를 들어 DB에서 상품을 하나 추가하고, 상품 개수 테이블에서 상품 개수를 1 증가해야하는 로직이 있다면, 상품을 하나 추가한 순간dirty read가 되면 추가된 상품은 조회가 되지만 상품개수는 증가하지 않은 상태가 된다. 위 예시처럼 부분적으로 갱신된 데이터는 혼란을 줄 수 있다.
- commit되지 않은 데이터를 읽어서 사용한 경우 읽어온 commit이 안 된 데이터가 abort가 되면 유효하지 않은 데이터를 사용하는 일이 발생할 수 있다.
Dirty Write
여러 트랜잭션에서 하나의 객체를 수정하려고 한다면, 제일 마지막에 커밋된 트랜잭션이 반영되게 되고 이를 dirty write라고 한다. 그렇다면 A가 먼저 수정을 진행하는데 뒤 늦게 수정을 한 B가 먼저 커밋을 넣게 되면 A의 수정내용은 사라지게 된다.
Read Commit 격리 수준에서는 가장 흔하게 row level locking을 사용한다. 기본적으로 객체를 변경하고 싶다면 객체에 대한 lock을 획득하고 수정후 커밋을 해야한다. 따라서 이미 lock이 걸린 객체에는 접근이 불가능해 먼저 동작하는 트랜잭션이 끝날때 까지 기다리게 된다. 하지만 같은 객체에 접근하는 트랜잭션이 많을 수록 늦게 접근한 트랜잭션은 오랜시간을 기다리게 된다는 단점이 있다.
Repeatable read(Snapshot Isolation)
repeatable read는 dirty read, dirty write를 금지하며 non-repeatable read도 막는다.
Non-Repeatable Read
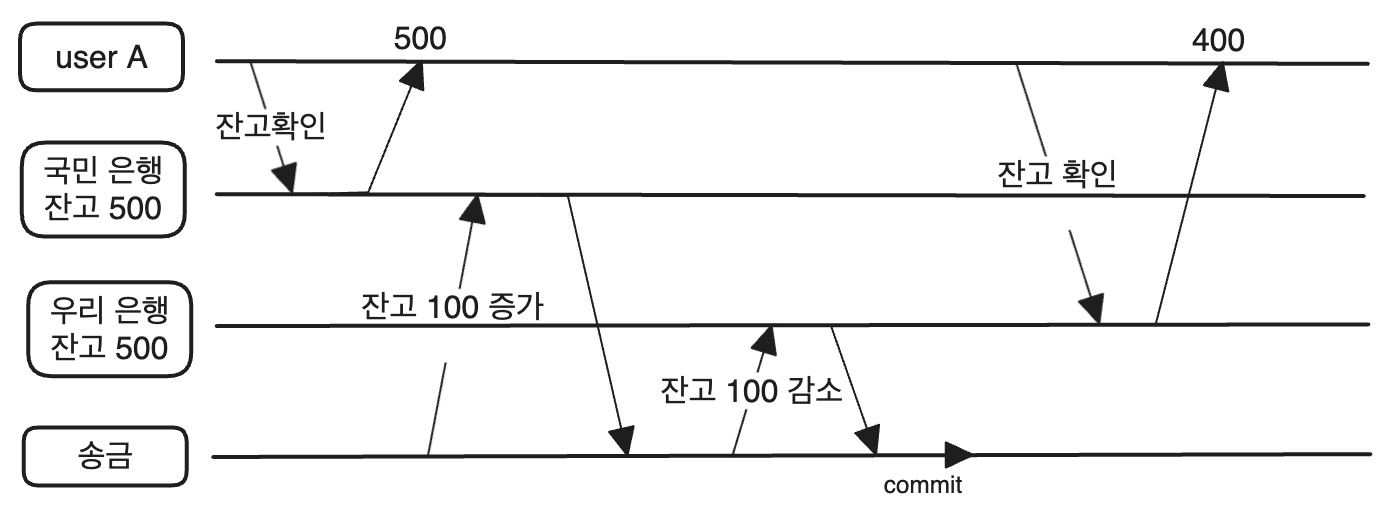
위는 사용자 A가 국민은행 잔고를 확인하고, 우리 은행 잔고를 확인하기 전에 우리 은행에서 100을 국민은행으로 송금하고 커밋한 상황인다. 그렇다면 사용자 A는 자신의 총 자산을 900만원으로 보게된다. 즉 하나의 트랜젝션에서 객체를 읽었지만 변화된 값을 읽게 되는 문제가 있다.
Repeatable Read는 이 문제를 막기위해 MVCC(Multi Version Concurrency Control, 다중 버전 동시성 제어)기법을 사용한다.
MVCC(Multi Version Concurrency Control, 다중 버전 동시성 제어)
DB는 객체마다 커밋된 여러개의 버전을 유지 할 수 있어야 한다. 객체마다 다른 시점의 DB를 볼 수 있어야 하기 때문에, 위의 2-1 그림에서 사용자 A는 송금이 발생전 버전의 객체를 보고 있어야 하듯이 말이다. 이렇게 커밋마다 여러개의 버전을 가지는 기법을 MVCC라고 한다.
PostgreSQL에서는 각 트랜잭션에 1씩 증가하는 trancation Id값을 부여하고 다음의 조건에 맞춰 일관된 스냅샵을 보여주게 된다.
- DB는 트랜잭션을 시작할때 그 시점에 진행중인(commit이나 abort가 되지않은) 모든 트랜잭션 목록을 만들고, 이 트랜잭션 데이터는 모두 무시한다. 설렁 나중에 커밋 되어도 무시한다.
- abort된 쓰기 데이터는 무시한다.
- 자신의 트랜잭션 id보다 더 큰 id를 가진 트랜잭션이 쓴 데이터는 커밋의 여부에 관계없이 모두 무시된다.
- 그 밖의 모든 데이터는 query로 볼 수 있다.
이러한 조건에 맞춰 그림 2-1을 repeatalbe read로 바꾸어 보면 사용자 A의 트랜잭션 id는 1이 되고 송금의 트랜잭션 id는 2가 된다. 즉 사용자 A는 우리은행 계좌에 접근할 때 400만원으로 바뀐 id가 2인 트랜젹을 보지 못하기 때문에(3번 규칙) 500만원을 응답하게 된다.
Repeatable Read의 핵심은 읽는 쪽에서 쓰는 쪽을 결코 차단하지 않고 쓰는 쪽에서 읽는 쪽을 결코 차단하지 않느다는 것이다.
Serializable(직렬성)
아래의 글에서 Write-Skew, Phantom-Read 같은 문제는 Repeatable-Read 수준에서도 해겨 하지 못한다. 따라서 Serializable이라는 가장 높은 수준의 격리기법이 존재한다.
[데이터 중심 애플리케이션 설계] 7장. Write에서의 동시성 문제
Lost Update(갱신 손실)Lost Update는 Committed Read 와 보다 낮은 수준의 격리 수준에서 나타나는 현상으로 하나의 DB 값에 대해 두가지 이상의 쓰기가 발생 했을 때 마지막의 쓰기만 반영이 되어 그 전의
snack-and-time.tistory.com
Serializable은 한번에 하나의 트랜잭션이 실행 됨을 보장하는 격리 수준이다. 마치 단일 스레드 루프에서 트랜잭션을 실행시킴으로서 한번에 하나의 트랜잭션을 실행하는 것과 같은 결과를 만들어 내야한다. (단일 스레드로 동작해야 한다는 것이 아니라 그것과 같은 결과를 보장해야 한다는 말이다.)
이러한 특징 때문에 클라이언트는 트랜잭션이 끝날 때 까지 늘 기다리고 있어야하는 단점이 존재한다. 이 단점을 해결 하는 방법으로는 스토어드 프로시저가 있지만
- 데이터베이스마다 일관 되지 못하다
- DB에서 실행되는코드는 관리, 디버깅, 버전 관리가 어렵고, 지표 수집에도 어려움이 있다.
- 잘 못 작성된 스토어드 프로시저는 DB 성능에 큰 악영향을 끼친다.
따라서 Serializable은 아래와 같은 조건에서 효율적으로 구현되어야 한다.
- 모든 트랜잭션은 작고 빨라야한다.
- 활성화된 데이터셋이 메모리에 적재될 수 있는 경우로 사용이 제한된다. 메모리가 아닌 디스크에 데이터가 저장되면 이에 접근할 때 큰 시간이 소모된다.
- 쓰기 처리량이 단일 CPU 코어에서 처리 할 수 있을 정도로 충분히 낮아야 한다.
- 여러 파티션에 걸친 트랜잭션도 쓸 수 있지만 이것을 사용할 수 있는 정도에는 엄격한 제한이 있다.
2PL(Two-Phase Locking)
2PL은 쓰기 트랜잭션에 있어서 쓰기와 읽기를 모두 막는다는 특징이 있다.
2PL에서는 Shared Mode(공유 모드) Lock과 Exclusive Mode(독점 모드) Lock이 있으며 다음과 같이 사용된다.
- 트랜잭션이 읽기를 원하면 Shared Mode Lock을 획득한다. Shared Mode Lock 여러 트랜잭션이 함께 Lock을 걸 수 있다. 하지만 Exclusive Mode Lock이 있다면 이 트랜잭션이 끝날때 까지 기다려야한다.
- 트랜잭션이 쓰기를 원하면 Exclusive Mode Lock을 획득해야 한다. Exclusive Mode Lock은 하나의 트랜잭션만이 획득할 수 있다.
- 읽기 중 쓰기를 해야 할 때는 Shared Mode Lock에서 Exclusive Mode Lock으로 업그레이드를 해야 한다.
- 트랜잭션이 잠금을 획득한 후에는 트랜잭션이 종료(Commit, Abort)될 때까지 잠금을 획득해야 한다.
(two phase인 이유는 트랜잭션이 시작할 때 잠금을 획득하고 트랜잭션이 끝날때 잠금을 해제 하기 때문에 2단계이다.)
2PL에서는 "교착 상태"라는 것이 자주 발생하는데, 교착 상태란, A 라는 트랜잭션이 a테이블에 독점 잠금을 가지고 B 라는 트랜잭션이 b테이블에 독점 잠금을 획득한 상태에서 A는 b에 B는 a에 접근할 때 두 트랜잭션이 끝나지 않는 상황을 말한다. 이 같은 경우에는 데이터베이스가 교착상태를 감지하고 A혹은 B 트랜잭션 중 하나를 Abort시킨다. Abort된 트랜잭션은 어플리케이션에서 다시 실행시켜야 한다.
2PL의 가장 큰 단점은 성능이다. DB에서는 트랜잭션의 최대 시간을 정해두지 않기 때문에 상황에 따라서는 무기한 대기를 해야하는 상황도 생길 수 있다.
Phantom Read
어떤 트랜잭션에서 실행 한 쓰기 결과가 다른 트랜잭션의 검색 쿼리 결과를 바꾸는 것을 팬텀이라 한다.
Phantom Read를 막기위한 직렬화 방법은 위의 글에 정리 되어 있다.
'computer science > DB' 카테고리의 다른 글
| #2 Redis Pub/Sub (0) | 2024.08.12 |
|---|---|
| [데이터 중심 애플리케이션 설계] 7장. Write에서의 동시성 문제 (0) | 2024.07.14 |
| 하나의 트랙잭션에서 insert 다음에 나오는 select 쿼리는 insert된 결과를 가지고 있을까? (0) | 2024.06.23 |
| [데이터 중심 애플리케이션 설계] ACID에서 애플케이션과 DB의 책임 분리 (1) | 2024.06.23 |
| #1 Redis type (0) | 2024.03.04 |